ETL Framework Redesign at WTW
At WTW, I led the end-to-end redesign and implementation of a metadata-driven ETL framework, replacing a legacy system. The new system is robust, flexible, and still actively used across the organization. It supports any data source compatible with Azure Databricks and Azure Data Factory (ADF), and emphasizes modularity, reuse, and observability.
Tech Stack
- Orchestration: Azure Data Factory
- Transformations: Azure Databricks, PySpark
- Metadata System: Azure SQL DB
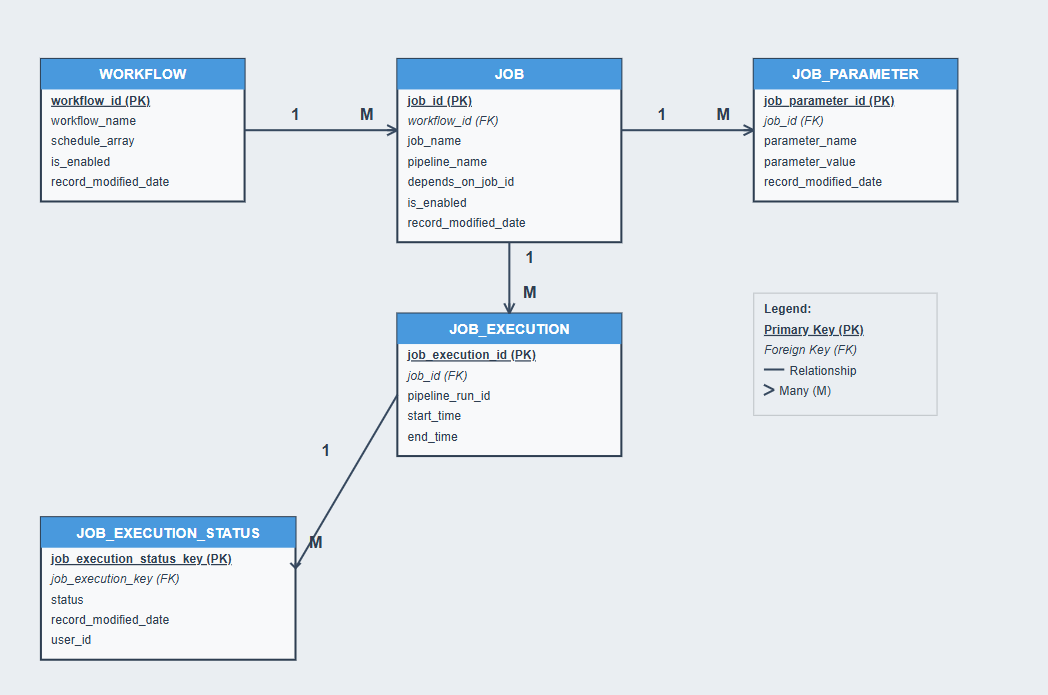
Metadata Entity Relationship Diagram
Field names have been modified for confidentiality while preserving core business logic.
Metadata-Driven Architecture
The core design principle was to shift from static, monolithic pipelines to dynamic, metadata-controlled workflows. Instead of building a new pipeline for each request, I designed workflows as collections of modular jobs, where each job is executed by a reusable pipeline. Workflow structure, job dependencies, parameters, and schedules are all stored in metadata tables. This approach dramatically reduced code duplication and allowed teams to scale workflow creation with minimal new development.
Example: When a new source—a file share on the company network—needed integration, I only created a new ingestion pipeline for that source. All transformation and warehouse loading logic reused existing pipelines through parameter configuration.
Dynamic Scheduling
I implemented a polling-based dynamic scheduler to replace ADF’s rigid, trigger-heavy system. Scheduling information is stored as JSON in the metadata table and parsed via a SQL view. A minutesSinceScheduled column identifies workflows ready to run (e.g., between 0–4 minutes late), which are then picked up by a central driver pipeline. This made it easier to enable/disable workflows using a simple isActive flag and avoided the silent failures previously caused by ADF triggers being turned off or misconfigured.
Job Dependency Management with DAG Logic
The legacy system scheduled jobs using hard-coded job order numbers. I replaced this with a directed acyclic graph (DAG) dependency system using a dependsOnJobId column in metadata.
A recursive CTE in SQL unrolled this dependency tree into a clean one-row-per-dependency format. This view is used to:
- Identify which jobs to run at the start of a workflow (no upstream dependencies).
- Dynamically queue successor jobs once predecessors finish.
This improved transparency, reduced human error, and made workflows much easier to scale or modify.
Notebook & Pipeline Standardization
Previously, developers created a new notebook for each new request, even if the logic was repetitive. I introduced a parameter-driven notebook template system, where common transformations could be reused by simply passing different parameters. Similarly, I introduced two reusable ADF pipelines for data-warehouse loads:
- PL_Warehouse_Overwrite: truncates and inserts into the target DW table.
- PL_Warehouse_Merge: stages data into an ETL table, then dynamically builds and executes a SQL MERGE statement.
This change also transitioned DW loading from Databricks JDBC/ODBC notebooks to native ADF copy activities, improving performance and scalability—especially for large datasets that had previously failed due to memory constraints.
Terminology & Documentation Clarity
To reduce confusion and improve adoption, I introduced a clear and consistent vocabulary:
- Workflows: The schedulable unit of execution, composed of jobs.
- Jobs: Tasks within a workflow, run by pipelines.
- Pipelines: Reusable components for ingesting, transforming, or loading data.
- Notebooks: A tool for pipeline implementation, not the orchestration unit.
To support long-term sustainability, I documented the entire framework internally, with detailed reference pages for every database object, notebook, and pipeline. I also onboarded teammates and led training, enabling the framework to scale quickly across use-cases.