Redesigning High Watermark Logic at WTW
When I joined WTW, I inherited an incremental data load framework responsible for populating dozens of tables in an Azure-based data warehouse. These tables were grouped into what the team called high watermark groups, and their processing logic depended on a pipeline start time. Notably, there was no table-level control of high watermarks beyond the bronze zone, and pre-advancing of watermarks occurred only for zones beyond bronze. The source-to-bronze zone processing was actually implemented correctly.
At the beginning of each run, the pipeline would set the high watermark to the current timestamp, then look back a fixed window, typically three hours, using that value in its filters. However, if a job failed, the watermark had already advanced by the next run and the data might be missed. To compensate, the team ran frequent manual and automated backfills, including a regular three-month backfill every Sunday.
Additionally, the ETL timestamps in the source OLTP database were not always reliable. One particularly fragile pattern used was:
SELECT *
FROM table_a
WHERE EXISTS (
SELECT 1
FROM table_b
WHERE table_a.col = table_b.col
AND table_b.timestamp > highWatermark
)
This indirect filtering often led to inconsistent results. The Azure data warehouse being loaded wasn't yet in use for reporting (which was still handled by an on-prem SSIS pipeline), so fixing this framework hadn't been a priority.
Redesigning the Watermark Strategy
This redesign was specifically for new projects; reworking the in-place incremental loads was not a priority, especially since the Azure data warehouse wasn't used for live reporting yet. I initially chose a hybrid approach to the existing framework, then eventually built an entirely new orchestration framework — read more about it here.
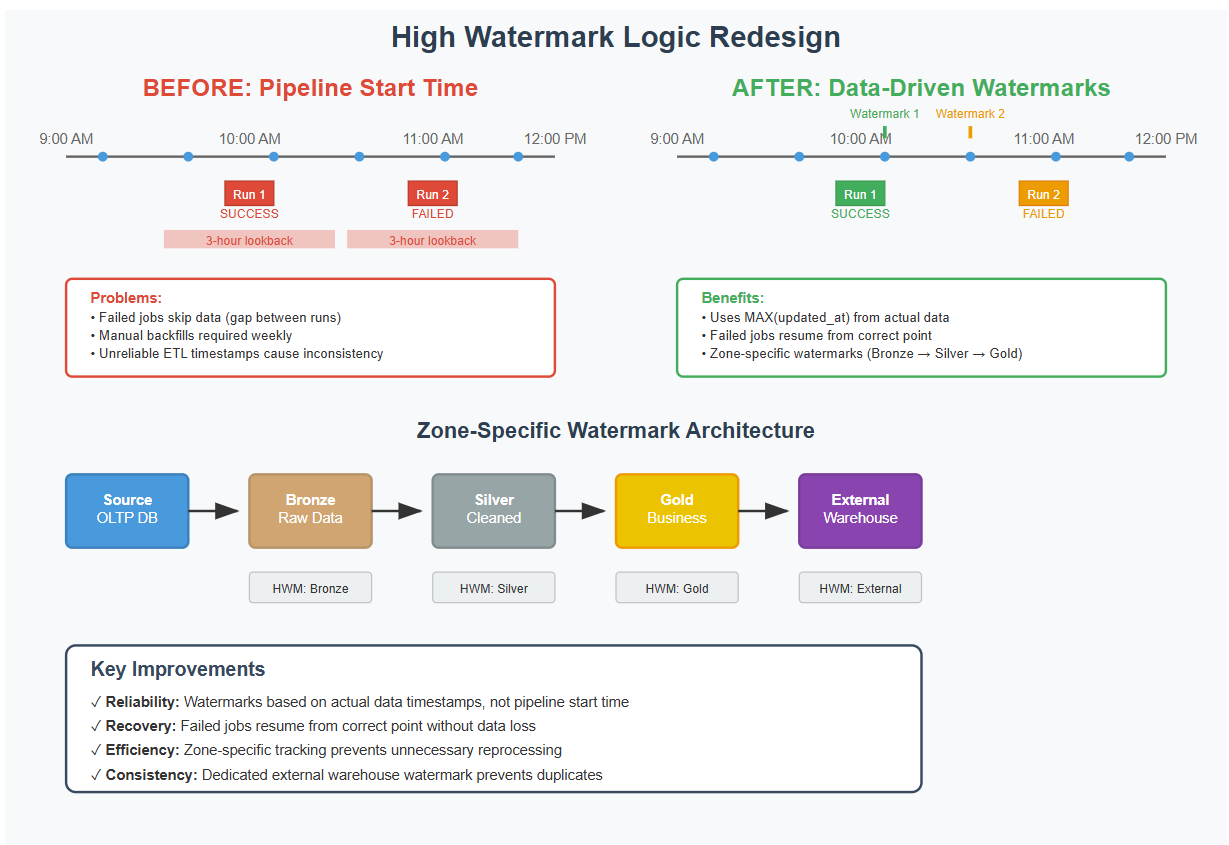
Architecture comparison showing the transition from pipeline-based to data-driven watermarks
Instead of using the pipeline's start time as the high watermark, which is unrelated to the data itself, I began storing the maximum value of the column actually used to filter the data (such as an updated_at timestamp). This ensured that the watermark was consistent with the data's own change history.
Why this matters: Using pipeline start time as a watermark risks skipping records if a job fails or runs late. Using the maximum value from the actual data ensures correctness, repeatability, and easier recovery from failure.
I also introduced zone-specific high watermarks. Each table tracked its watermark independently in the bronze, silver, and gold zones of our lakehouse. For example, if a job succeeded in loading bronze but failed in silver, it wouldn't reprocess the entire dataset, just the delta from the previous zone's high watermark.
Since our external SQL warehouse, used for business reporting, only received